مقدمه:
برای استفاده از امکانات بلاک دیتا (Data Application Block) باید 4 اسمبلی زیر را به برنامه خود اضافه کنید. البته تحت شرایطی ممکن است نیاز به اضافه نمودن اسمبلی های دیگری نیز باشد که در آینده ملاحظه خواهید نمود.
تذکر بسیار مهم:
اسمبلی های مربوطه را باید از دایرکتوری نصب برنامه کپی کنید (یا ارجاع دهید). به طور مثال برای بنده این اسمبلی ها در مسیر زیر ذخیره شده اند.
C:\Program Files\Microsoft Enterprise Library 5.0\Bin
هنگام کار با ابزار پیکربندی این کتابخانه، خصوصیاتی از قبیل PublicKeyToken و Version و ... تولید می شود که مختص اسمبلی هایی می باشد که به طور پیشفرض در این نسخه از کتابخانه تعبیه شده اند و هنگام نصب در محل دایرکتوری برنامه کپی می شوند.
<section name="dataConfiguration" type="Microsoft.Practices.EnterpriseLibrary.Data.Configuration.DatabaseSettings,
Microsoft.Practices.EnterpriseLibrary.Data,
Version=5.0.414.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" requirePermission="true" />
اگر به خاطر بیاورید در مقالات قبلی هنگام شرح نحوه نصب این کتابخانه، دیدیم که در انتهای مراحل نصب، یک ورژن دیگر از این اسمبلی ها در همان زمان کامپایل شده و کنار محل ذخیره سازی سورس برنامه، ذخیره شدند. در صورتی که بخواهیم از این اسمبلی ها استفاده کنیم باید خصوصیت PublicKeyToken را تغییر داده و یا حذف نماییم. این مسائل مربوط به Strong Name بودن اسمبلی ها می شود و ما از بحث بیشتر در مورد آن خودداری می کنیم.
از میان 5 اسمبلی ذکر شده در قسمت بالا، چهار تای اول برای استفاده از تمامی بلاک ها الزامی می باشند ولی اسمبلی پنجم مختص بلاک دیتا می باشد.
برای استفاده از امکانات بلاک دیتا باید فضاهای نامی زیر را به برنامه اضافه کنید.
-
Microsoft.Practices.EnterpriseLibrary.Data
-
Microsoft.Practices.EnterpriseLibrary.Common.Configuration
-
System.Data
-
System.Data.Common
اگر بخواهید از مکانیزم تزریق وابستگی (Dependency Injection) که توسط بلاک Unity ایجاد شده است، استفاده نمایید باید فضاهای نامی زیر را نیز به برنامه اضافه کنید (ما در این سلسله مقالات از این روش استفاده نخواهیم کرد).
-
System.Configuration
-
Microsoft.Practices.Unity
-
Microsoft.Practices.Unity.Configuration
نحوه نمونه سازی اشیاء (Object Instantiation) در کتابخانه Enterprise Library 5:
در نسخه های قبلی این کتابخانه، کلاس هایی به شکل Factory وجود داشتند که وظیفه نمونه سازی اشیاء را به عهده می گرفتند. به طور مثال کلاسی به نام DatabaseFactory وجود داشت (و البته هنوز هم وجود دارد!) که حاوی متدی به نام CreateDatabse بود. این متد یک نمونه شیء از کلاس Database را برمی گرداند که با استفاده این کلاس تمام اعمال مربوط به پایگاه داده انجام می شود. در قسمت زیر نحوه نمونه سازی کلاس Database توسط کلاس DatabaseFactory را ملاحظه می کنید.
Database db = DatabaseFactory.CreateDatabase();
پس از ارائه آخرین نسخه، استفاده از این روش منسوخ شده است. البته به منظور سازگار بودن با نسخه های پیشین همچنان این امکان وجود دارد که از این روش استفاده کنید ولی این عمل توصیه نمی شود و ما نیز از این روش استفاده نخواهیم نمود.
دو روش برای نمونه سازی اشیاء در کتابخانه Enterprise Library 5 توصیه شده است.
-
استفاده از Unity Service Locator (روش ساده تر)
-
استفاده از Unity Container (روش پیچیده تر)
نمونه سازی اشیاء به روش Unity Service Locator:
به نحوه نمونه سازی کلاس Database با استفاده از روش Unity Service Locator دقت کنید.
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
نمونه سازی اشیاء در کلیه بلاک ها با استفاده از کلاس EnterpriseLibraryContainer انجام می شود. این کلاس دارای یک پراپرتی استاتیک به نام Current می باشد که این پراپرتی یک آبجکت از نوع IServiceLocator را برمی گرداند. اینترفیس IServiceLocator دارای یک متد جنریک به نام GetInstance می باشد که نام کلاس مورد تقاضای ما را (در اینجا Database) را دریافت نموده و عمل نمونه سازی از آن را انجام می دهد.
متد GetInstance دارای یک Overload دیگر نیز می باشد که نام رشته اتصال (Connection String) خاصی را که علاقه مند هستیم از آن استفاده کنیم را دریافت می کند. در قطع کد بالا با توجه به اینکه ما نام رشته اتصال پایگاه داده را به این متد نفرستاده ایم پس نمونه سازی با استفاده از رشته اتصال پیشفرض (که در فایل پیکربندی مشخص شده است) انجام می شود. ولی در صورت تمایل می توانید رشته اتصال مورد نظر خود را صریحا اعلام کنید تا نمونه سازی بر اساس آن انجام شود.
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>("ConnectionString2");
نمونه سازی اشیاء به روش Unity Container:
قبل از اینکه به معرفی اجمالی این روش بپردازیم باید بدانید که در حقیقت در روش Unity Service Locator نیز از Unity Container برای نمونه سازی اشیاء استفاده می شود ولی برای اینکه برنامه نویس به طور مستقیم درگیر کار با Unity Container نگردد، این عمل به شکل داخلی و پنهان انجام می شود و بنابراین شما فقط کافیست که فقط متد GetInstance را فراخوانی کنید.
در روش نمونه سازی اشیاء با استفاده از Unity Container شما امکان پیدا می کنید که به طور مستقیم با Unity Container که یک Dependency Injection Container می باشد، کار کنید. همانطور که قبلا هم بار ها ذکر کرده ایم، مبحث مربوط به تزریق وابستگی (Dependency Injection) خارج از اهداف این مقاله می باشد و ما قصد ورود به آن را نداریم. با استفاده از Unity Container شما می توانید حتی کلاس های داخلی برنامه خود را با استفاده از مکانیزم تزریق وابستگی نمونه سازی کنید که البته این مسئله نیاز به انجام اعمال بیشتری نیز دارد.
نمونه سازی اشیاء با استفاده از این روش به شکل زیر انجام می پذیرد.
var container = new UnityContainer();
container.AddNewExtension<EnterpriseLibraryCoreExtension>();
Database db3 = container.Resolve<Database>();
ما در این سلسله مقالات از روش Unity Service Locator برای نمونه سازی اشیاء استفاده خواهیم نمود.
ورود به مبحث بلاک دیتا:
تمامی اعمال متداول CRUD (یعنی Create, Read, Update, Delete) توسط بلاک دیتا با استفاده از کلاس Database انجام می شود. کلاس Database از نوع abstract می باشد که برای پایگاه های داده مختلف، پیاده سازی های مختلفی از آن انجام شده است. از جمله این پیاده سازی ها می توان به SqlDatabase، SqlCeDatabase، GenericDatabase، OracleDatabase اشاره نمود.
معمولا توابعی که در میان تمامی پایگاه های داده عملکرد یکسانی دارند در کلاس Database تعریف شده اند و توابعی که مخصوص پایگاه داده مشخصی هستند در کلاسی که وظیفه پیاده سازی را به عهده گرفته است تعریف می شوند. به طور مثال توابعی که به شکل آسنکرون اجرا می شوند از قبیل BeginExecuteNonQuery و BeginExecuteReader و غیره خاص پایگاه داده Microsoft SQL Server می باشند و بنابراین در کلاس SqlDatabase تعریف شده اند و در نتیجه اگر بخواهید از این توابع استفاده کنید باید کلاس Database را به SqlDatabase تبدیل کنید. در صورتی که علاقه مند باشید می توانید شما نیز برای پایگاه داده دلخواه خود یک پیاده سازی از کلاس Database بنویسید.
کلاس Database دارای متدهای فراوانی می باشد که مهمترین آن ها را در شکل زیر ملاحظه می نمایید. با استفاده از این چند متد می توانیم تمامی اعمال متداول بر روی پایگاه داده را انجام دهیم.
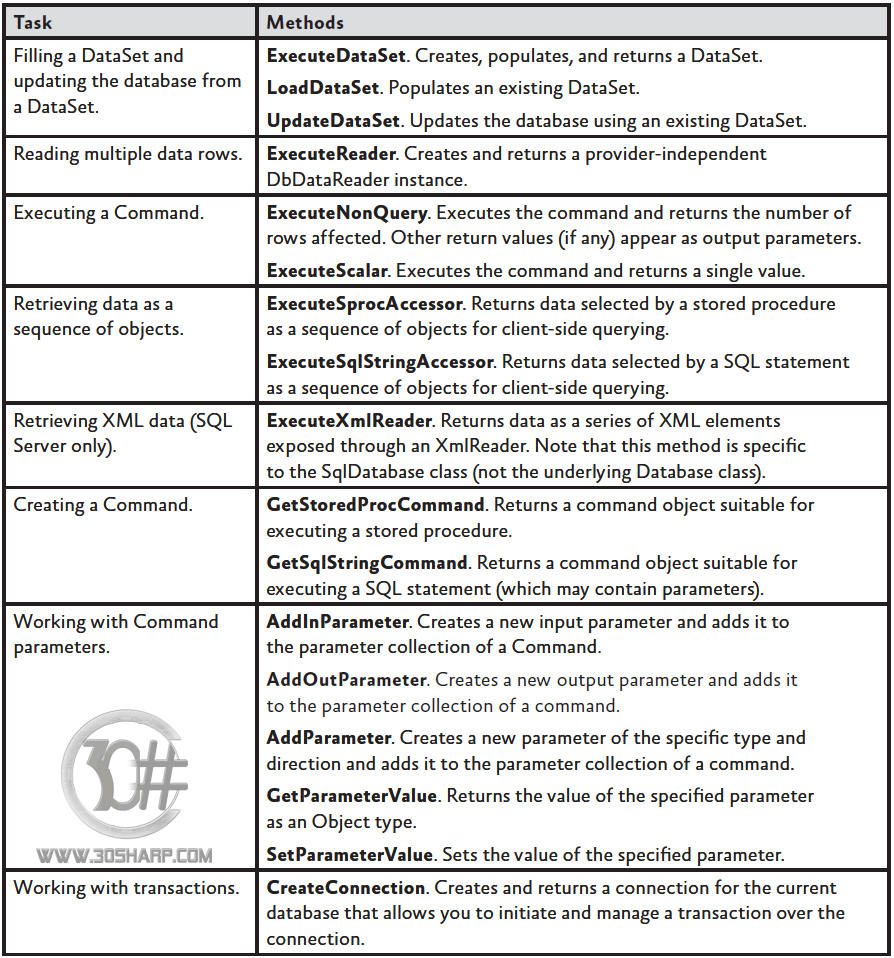
هر یک از این متدها دارای Overload های متعددی می باشند و بنابراین هر یک از اعمال مربوط به پایگاه داده را می توان از چندین روش انجام داد. ما در این مقاله سعی می کنیم بهترین روش ها را معرفی نماییم.
فرض کنید جدولی به نام Student با ساختار زیر در پایگاه داده داریم که دارای تعدادی رکورد می باشد و قصد داریم اعمال متداول را بر روی آن انجام دهید.
CREATE TABLE [Student](
[StudentId] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [nvarchar](100) NOT NULL,
[LastName] [nvarchar](100) NOT NULL,
[Age] [int] NOT NULL,
)
کلاسی نیز به نام Studentداریم که برای نگهداری اطلاعات دانشجویان استفاده می شود.
public class Student
{
public int StudentId { get; set; }
public string FirstName { get; set; }
public string LirstName { get; set; }
public int Age { get; set; }
}
انجام اعمال مختلف بر روی پایگاه داده معمولا از دو طریق انجام می پذیرد:
-
Stored Procedure: روال های ذخیره شده در پایگاه داده می باشند که ما در این مقاله آن را پروسیجر خطاب می کنیم (مانند uspInsertStudent).
-
SQL Comment: یک رشته دستور قابل فهم برای پایگاه داده می باشد (مانند Select * from Student).
Overload های توابع کلاس Database به طور کلی به دو دسته تقسیم می شوند. دسته اول Overloadمی باشند که یک پارامتر های آن ها از نوع DbCommand می باشد و به وسیله این متدها همه نوع اعمالی را می توان انجام داد. دسته دوم Overload هایی هستند که نام یک پروسیجر یا یک دستور SQL را به همراه مجموعه ای از مقادیر (به عنوان مقادیر پارامتر ها) گرفته و عملیات را روی پایگاه داده انجام می دهند. Overload های نوع اول انعطاف پذیر تر هستند در حالیکه Overload های نوع دوم مقداری محدودیت دارند ولی در عوض استفاده از آن ها ساده تر می باشد. در ادامه مقاله و هنگام طرح مثال ها با این دو گروه بیشتر آشنا خواهید شد.
تذکر:
قبل از طرح مثال ها تاکید می شود که سورس کامل این مقاله از طریق لینک بالای صفحه قابل دریافت می باشد.
مثال اول: بازیابی اطلاعات دانش آموزی که شناسه او 1 بوده و سن او 20 سال می باشد
پروسیجر:
CREATE PROCEDURE uspGetStudent
(
@studentId INT,
@age INT
)
AS
SELECT * FROM Student WHERE StudentId = @studentId AND Age = @age
نوشتن متدی برای انجام این کار با استفاده از پروسیجر:
private Student GetStudenByUsingProcedure(int studentId, int age)
{
Student student = null;
string procedureName = "uspGetStudent";
object[] values = new object[] { studentId, age };
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
using (IDataReader reader = db.ExecuteReader(procedureName, values))
{
if (reader.Read())
{
student = new Student();
student.StudentId = (int)reader["StudentId"];
student.FirstName = reader["FirstName"].ToString();
student.LastName = reader["LastName"].ToString();
student.Age = (int)reader["Age"];
}
}
return student;
}
در روش متد بالا، مقادیری که قرار است برای پروسیجر ارسال شود را داخل آرایه ای از اشیاء به نام valuesریخته ایم. دقت کنید که ترتیب قرارگیری پارامتر ها باید با ترتیب دریافت پارامتر ها در پروسیجر یکسان باشد. در متد بالا ما ابتدا studentId و سپس age را اضافه کرده ایم. سپس یک نمونه سازی از نوع کلاس Database انجام داده ایم. همانطور که در مقالات قبلی ذکر شد، با توجه به اینکه در هنگام تعریف رشته اتصال پایگاه داده (Connection String) در فایل پیکربندی ما پارامتر providerName را برابر System.Data.SqlClient قرار داده ایم، نوع شیء ساخته شده برای کلاس Database از نوع SqlDatabase خواهد بود.
سپس با استفاده از یکی از Overload های متد ExecuteReader که نام پروسیجر را به عنوان پارامتر اول و مقادیر را به عنوان پارامتر دوم دریافت می کند، دستور خود را اجرا می کنیم. مقدار برگشتی متد ExecuteReader را به شکل IDataReader دریافت کرده ایم. درحقیقت IDataReader در اینجا از نوع SqlDataReader می باشد که در ADO.NET آن را به خوبی می شناسیم. در نهایت مقادیر را از IDataReader خوانده و یک شیء از Studentرا پر نموده ایم.
معادل متد بالا را سعی کنید با استفاده از ADO.NET بنویسید تا متوجه شوید چقدر کار ساده تر شده است. فرض کنید پروسیجر uspGetStudent تعداد زیادی پارامتر داشت. با استفاده از روش بالا تنها تفاوت این بود که سایر پارامتر ها را نیز باید به آرایه values اضافه می کردیم ولی در روش ADO.NET معمولی باید چندین خط کد برای اضافه نمودن پارامتر ها و مقادیر آن ها نوشته می شد. ضمنا عملیات باز و بسته نمودن اتصال پایگاه داده به بهترین وجه و داخل خود بلاک دیتا انجام می شود و شما اثری از آن را در قطعه کد بالا نمی بینید!
نوشتن متدی برای انجام این کار با استفاده از دستورات SQL:
private Student GetStudenByUsingSQL(int studentId, int age)
{
Student student = null;
string sql = "SELECT * FROM Student WHERE StudentId=@studentId AND Age=@age";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DbCommand command = db.GetSqlStringCommand(sql);
db.AddInParameter(command, "@studentId", DbType.Int32, studentId);
db.AddInParameter(command, "@age", DbType.Int32, age);
using (IDataReader reader = db.ExecuteReader(command))
{
if (reader.Read())
{
student = new Student();
student.StudentId = (int)reader["StudentId"];
student.FirstName = reader["FirstName"].ToString();
student.LastName = reader["LastName"].ToString();
student.Age = (int)reader["Age"];
}
}
return student;
}
در متد بالا ما از یک روش دیگر که همان استفاده از DbCommand می باشد، استفاده کرده ایم. ابتدا دستور sql را به متد GetSqlStringCommand ارسال کرده ایم تا شیء DbCommand مناسب برای دستور SQL ساخته شود. سپس با استفاده از متد AddInParameter مقادیر را به پارامتر ها نسبت داده ایم و در نهایت شیء DbCommand را برای اجرای دستور به متد ExecuteReader ارسال کرده ایم.
مثال دوم: بازیابی مشخصات تمام دانشجویانی که سن آن 20 سال می باشد:
پروسیجر:
CREATE PROCEDURE uspGetStudentsByAge
(
@age INT
)
AS
SELECT * FROM Student WHERE Age=@age
نوشتن متدی برای انجام این کار با استفاده از پروسیجر:
private List<Student> GetStudentsByAgeUsingProcedure(int age)
{
Student student = null;
List<Student> students = new List<Student>();
string procedureName = "uspGetStudentsByAge";
object[] values = new object[] { age };
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
using (IDataReader reader = db.ExecuteReader(procedureName, values))
{
while (reader.Read())
{
student = new Student();
student.StudentId = (int)reader["StudentId"];
student.FirstName = reader["FirstName"].ToString();
student.LastName = reader["LastName"].ToString();
student.Age = (int)reader["Age"];
students.Add(student);
}
}
return students;
}
همانطور که ملاحظه می کنید، منطق کار تغییر چندانی نکرد و فقط ما به جای اینکه اطلاعات یک دانش آموز را بازیابی کنیم، اطلاعات تعدای از آن ها را بازیابی نموده ایم.
نوشتن متدی برای انجام این کار با استفاده از دستورات SQL:
private List<Student> GetStudentsByAgeUsingSQL(int age)
{
Student student = null;
List<Student> students = new List<Student>();
string sql = "SELECT * FROM Student WHERE Age=@age";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DbCommand command = db.GetSqlStringCommand(sql);
db.AddInParameter(command, "@age", DbType.Int32, age);
using (IDataReader reader = db.ExecuteReader(command))
{
while (reader.Read())
{
student = new Student();
student.StudentId = (int)reader["StudentId"];
student.FirstName = reader["FirstName"].ToString();
student.LastName = reader["LastName"].ToString();
student.Age = (int)reader["Age"];
}
}
return students;
}
در این متد هم تغییر چندانی ایجاد نکردیم.
مثال سوم: بازیابی لیست تمامی دانشجویان:
در مثال های قبل ما مقادیری را برای پروسیجر یا دستور SQL ارسال می کردیم. در این مثال هیج مقداری را ارسال نمی کنیم و فقط قصد داریم لیست تمامی دانشجویان را بازیابی کنیم.
پروسیجر:
CREATE PROCEDURE uspGetAllStudents
AS
SELECT * FROM Student
نوشتن متدی برای انجام این کار با استفاده از پروسیجر:
private List<Student> GetAllStudentsUsingProcedure()
{
Student student = null;
List<Student> students = new List<Student>();
string procedureName = "uspGetAllStudents";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
using (IDataReader reader = db.ExecuteReader(CommandType.StoredProcedure, procedureName))
{
while (reader.Read())
{
student = new Student();
student.StudentId = (int)reader["StudentId"];
student.FirstName = reader["FirstName"].ToString();
student.LastName = reader["LastName"].ToString();
student.Age = (int)reader["Age"];
students.Add(student);
}
}
return students;
}
این بار از یک Overload متد ExecuteReader استفاده کرده ایم که CommandType.StoredProcedure را به عنوان پارامتر اول گرفته و نام پروسیجر را به عنوان پارامتر دوم دریافت می کند.
نوشتن متدی برای انجام این کار با استفاده از دستورات SQL:
دقیقا مانند متد بالا می باشد با این تفاوت که این بار CommandType را از نوع CommandType.Text تعیین می کنیم.
private List<Student> GetAllStudentsUsingSQL()
{
Student student = null;
List<Student> students = new List<Student>();
string sql = "SELECT * FROM Student";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
using (IDataReader reader = db.ExecuteReader(CommandType.Text, sql))
{
while (reader.Read())
{
student = new Student();
student.StudentId = (int)reader["StudentId"];
student.FirstName = reader["FirstName"].ToString();
student.LastName = reader["LastName"].ToString();
student.Age = (int)reader["Age"];
students.Add(student);
}
}
return students;
}
مثال چهارم: بازیابی سن یک دانشجو:
گاهی اوقات خروجی دستور SQL ما یک تک مقدار می باشد. هر چند از روش های گفته شده در بالا نیز می توان این عمل را انجام داد ولی با بهتر است که با عملکرد تابع ExecuteScalar نیز آشنا شوید.
پروسیجر:
CREATE PROCEDURE uspGetStudentAge
(
@studentId INT
)
AS
SELECT Age FROM Student WHERE StudentId=@studentId
نوشتن متدی برای انجام این کار با استفاده از پروسیجر:
private int GetStudenAgeUsingProcedure(int studentId)
{
int age = -1;
string procedureName = "uspGetStudentAge";
object[] values = new object[] { studentId };
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
object result = db.ExecuteScalar(procedureName, values);
if (result != null)
{
age = Convert.ToInt32(result);
}
return age;
}
ابتدا مقدار age را به طور پیشفرض برابر 1- تعیین کرده ایم تا اگر اصلا چنین دانش آموزی وجود نداشت متوجه آن شویم. عملکرد سایر قسمت های کد کاملا شفاف می باشد.
نوشتن متدی برای انجام این کار با استفاده از دستورات SQL:
private int GetStudenAgeUsingSQL(int studentId)
{
int age = -1;
string sql = "SELECT Age FROM Student WHERE StudentId=@studentId";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DbCommand command = db.GetSqlStringCommand(sql);
db.AddInParameter(command, "@studentId", DbType.Int32, studentId);
object result = db.ExecuteScalar(command);
if (result != null)
{
age = Convert.ToInt32(result);
}
return age;
}
عملکرد متد بالا نیز کاملا شفاف می باشد.
مثال پنجم: بازیابی اطلاعات دانشجویان به شکل یک دیتاست(DataSet):
تاکنون تمامی اطلاعات را با استفاده از IDataReader بازیابی نموده ایم. اکنون قصد داریم اطلاعات را به صورت یک دیتاست بازیابی کنیم. برای انجام این کار در بلاک دیتا از دو متد ExecuteDataSet و LoadDataSet استفاده می شود. عملکرد این دو متد یکسان می باشد با این تفاوت که در متد ExecuteDataSet یک شیء دیتاست جدید ایجاد شده و برگردانده می شود در حالیکه در متد LoadDataSet بر روی دیتاستی که در حال حاضر موجود است (باید به عنوانی یک پارامتر برای این متد بفرستیم) تغییرات اعمال می شود.
CREATE PROCEDURE uspGetAllStudents
AS
SELECT * FROM Student
نوشتن متدی برای انجام این کار با استفاده از پروسیجر:
private DataSet GetAllStudentsDatasetUsingProcedure()
{
Student student = null;
string procedureName = "uspGetAllStudents";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DataSet ds = db.ExecuteDataSet(CommandType.StoredProcedure, procedureName);
return ds;
}
در قطعه کد بالا از متد ExecuteDataSet استفاده شده است.
نوشتن متدی برای انجام این کار با استفاده از دستورات SQL:
private DataSet GetAllStudentsDatasetUsingSQL()
{
Student student = null;
string sql = "SELECT * FROM Student";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DataSet ds = db.ExecuteDataSet(CommandType.Text, sql);
return ds;
}
مثال ششم: بازیابی اطلاعات با فرمت XML:
برای بازیابی اطلاعات به شکل XML از متد ExecuteXmlReader استفاده می شود. این متد مخصوص پایگاه داده Microsoft SQL Server می باشد و بنابراین تعریف آن در کلاس SqlDatabase انجام شده است. برای استفاده از این متد باید کلاس Database را تبدیل به SqlDatabase کنیم. متدهای آسنکرون BeginExecuteXmlReader و EndExecuteXmlReader نیز در این کلاس تعریف شده اند که در صورت نیاز می توانید از آن ها استفاده کنید.
در قطعه کد زیر ما لیست مشخصات تمامی دانش آموزان را به شکل یک رشته XML بازیابی نموده ایم.
private string GetAllStudentsAsXML()
{
Student student = null;
string sql = "SELECT * FROM Student FOR XML AUTO";
SqlDatabase db = EnterpriseLibraryContainer.Current.GetInstance<Database>() as SqlDatabase;
DbCommand command = db.GetSqlStringCommand(sql);
string result = "";
try
{
using (XmlReader reader = db.ExecuteXmlReader(command))
{
// Read Data
while (!reader.EOF)
{
if (reader.IsStartElement())
{
result += reader.ReadOuterXml();
}
}
}
}
finally
{
// Close Connection
if (command.Connection != null)
{
command.Connection.Close();
}
}
return result;
}
در دستور SQL قطعه کد بالا از عبارت FOR XML AUTO برای بازیابی شدن اطلاعات با فرمت XML استفاده کرده ایم و سپس برای دسترسی به این متد شیء Database را تبدیل به SqlDatabase کرده ایم. خروجی متد ExecuteXmlReader از نوع XmlReader می باشد که با پیمایش آن می توانیم اعمال مورد نظر خود را انجام دهیم.
تذکر: هنگام استفاده از متد ExecuteXmlReader حتما باید اتصال پایگاه داده (Connection) را صریحا ببندید. این متد پس از اجرا اتصال را نمی بندد و حتی XmlReader نیز هنگامی که Dispose می شود باز هم اتصال باز می ماند. ما در متد بالا در قسمت finally اتصال را بسته ایم.
محتویات متغیر result در قطع کد بالا مشابه زیر می باشد.
<Student StudentId="1" FirstName="Morteza" LastName="Sahragard" Age="20" />
<Student StudentId="2" FirstName="Ali" LastName="Rahmani" Age="20" />
خوب، روش های مهم بازیابی اطلاعات را بررسی کردیم. اکنون به سراغ وارد نمودن اطللاعات جدید می رویم.
مثال هفتم: وارد نمودن رکورد جدید در پایگاه داده (بدون مقدار برگشتی):
به طور معمول وارد نمودن اطلاعات در پایگاه داده یا با مقدار برگشتی (Output Value) می باشد و یا بدون آن. در این مثال بدون مقدار برگشتی را بررسی می کنیم.
پروسیجر:
CREATE PROCEDURE uspInsertUserWithoutReturnValue
(
@firstName nvarchar(100),
@lastName nvarchar(100),
@age int
)
AS
INSERT INTO dbo.Student( FirstName, LastName, Age )
VALUES ( @firstName,@lastName, @age )
نوشتن متدی برای انجام این کار با استفاده از پروسیجر:
private void InsertUserWithoutReturnValueUsingProcedure(string firstName, string lastName, int age)
{
string procedureName = "uspInsertUserWithoutReturnValue";
object[] values = new object[] { firstName, lastName, age };
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
db.ExecuteNonQuery(procedureName, values);
}
ملاحظه می کنید که تنها تغییر این متد استفاده از ExecuteNonQuery می باشد و سایر قضایا همانند متدهای قبلی می باشد.
نوشتن متدی برای انجام این کار با استفاده از دستورات SQL:
private void InsertUserWithoutReturnValueUsingSQL(string firstName, string lastName, int age)
{
string sql = "INSERT INTO dbo.Student( FirstName, LastName, Age)VALUES ( @firstName,@lastName, @age)";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DbCommand command = db.GetSqlStringCommand(sql);
db.AddInParameter(command, "@firstName", DbType.String, firstName);
db.AddInParameter(command, "@lastName", DbType.String, lastName);
db.AddInParameter(command, "@age", DbType.Int32, age);
db.ExecuteNonQuery(command);
}
مثال هفتم: وارد نمودن رکورد جدید در پایگاه داده (همراه با مقدار برگشتی):
پروسیجر:
CREATE PROCEDURE uspInsertUserWithReturnValue
(
@firstName nvarchar(100),
@lastName nvarchar(100),
@age INT,
@studentId INT OUTPUT
)
AS
INSERT INTO dbo.Student( FirstName, LastName, Age )
VALUES ( @firstName,@lastName, @age )
SET @studentId=SCOPE_IDENTITY();
RETURN
نوشتن متدی برای انجام این کار با استفاده از پروسیجر:
private int InsertUserWithReturnValueUsingProcedure(string firstName, string lastName, int age)
{
int studentId = -1;
string procedureName = "uspInsertUserWithReturnValue";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DbCommand command = db.GetStoredProcCommand(procedureName);
db.AddInParameter(command, "@firstName", DbType.String, firstName);
db.AddInParameter(command, "@lastName", DbType.String, lastName);
db.AddInParameter(command, "@age", DbType.Int32, age);
//add output parameter
db.AddOutParameter(command, "@studentId", DbType.Int32, int.MaxValue);
int numberOfAffectedRows = db.ExecuteNonQuery(command);
if (numberOfAffectedRows > 0)
{
studentId = (int)db.GetParameterValue(command, "@studentId");
}
return studentId;
}
با توجه به اینکه ما نیاز به دریافت پارامتر خروجی پروسیجر داریم، از روش DbCommand استفاده کرده ایم. دقت کنید که برای ساخت DbCommand این بار از متد GetStoredProcCommand استفاده نموده ایم چون قصد داریم شیء DbCommand با استفاده از پروسیجر ساخته شود. پارامتر خروجی را با استفاده از متد AddOutParameter اضافه کرده ایم. متد ExecuteNonQuery همانند مشابه خود در ADO.NET معمولی، پس از اجرا دستور، تعداد رکوردهایی که مورد تاثیر اجرای دستور قرار گرفته اند را برمی گرداند. در نهایت با استفاده از متد GetParameterValue مقدار پارامتر خروجی را بازیابی نموده ایم.
نوشتن متدی برای انجام این کار با استفاده از دستورات SQL:
private int InsertUserWithReturnValueUsingSQL(string firstName, string lastName, int age)
{
int studentId = -1;
string sql = "INSERT INTO dbo.Student( FirstName, LastName, Age )VALUES ( @firstName,@lastName, @age );" +
"SET @studentId=SCOPE_IDENTITY();return;";
Database db = EnterpriseLibraryContainer.Current.GetInstance<Database>();
DbCommand command = db.GetSqlStringCommand(sql);
db.AddInParameter(command, "@firstName", DbType.String, firstName);
db.AddInParameter(command, "@lastName", DbType.String, lastName);
db.AddInParameter(command, "@age", DbType.Int32, age);
//add output parameter
db.AddOutParameter(command, "@studentId", DbType.Int32, int.MaxValue);
int numberOfAffectedRows = db.ExecuteNonQuery(command);
if (numberOfAffectedRows > 0)
{
studentId = (int)db.GetParameterValue(command, "@studentId");
}
return studentId;
}
روند کار شبیه متد قبلی می باشد با این تفاوت که این بار به جای پروسیجر از دستور SQL استفاده نموده ایم و از متد GetSqlStringCommand جهت ساخت شیء DbCommand استفاده کردیم.
بروز رسانی و حذف اطلاعات:
بروز رسانی و حذف اطلاعات دقیقا همانند ورود اطلاعات جدید که در بالا بحث کردیم توسط متد ExecuteNonQuery انجام می شود با این تفاوت که محتوای دستور SQL یا پروسیجر از Delete یا Update استفاده می کند.
استفاده از Transaction:
در هنگام کار با پایگاه داده گاهی نیاز است از Transaction استفاده کنیم. این موضوع معمولا زمانی اتفاق می افتد که نیاز داریم چندین تغییر در پایگاه داده ایجاد کنیم و این تغییرات وابسته به یکدیگر می باشند. اگر انجام یکی از تغییرات با شکست روبرو شود (و یا به هر نحوی نتیجه مور نظر ما حاصل نگردد) باید تمامی تغییرات بی اثر (Rollback) گردند.
یکی از روش های معروف برای اعمال Transaction، استفاده از کلاس TranasctionScope می باشد که به صورت توزیع شده نیز عمل می کند. یعنی حتی می توان تغییرات انجام شده بر روی چند پایگاه داده متفاوت را بی اثر نمود.
استفاده از این کلاس بسیار ساده می باشد و کافیست که قطعه کد های خود را داخل بلاک TranasctionScope بگذاریم.
using (TransactionScope scope= new TransactionScope(TransactionScopeOption.RequiresNew))
{
// perform data access here
scope.Complete();
}
با فراخوانی متد Complete در انتهای تمامی عملیات، تغییرات اعمال می شوند و در غیر اینصورت تغییرات بی اثر می شوند. به یاد داشته باشید که کلاس TranasctionScope در پس زمینه خود از امکانات +COM استفاده می کند و در نتیجه ملاحظات +COM در اینجا نیز باید مد نظر قرار گیرد. ضمنا برای استفاده از این کلاس باید ابتدا ارجاع (Reference) اسمبلی System.Transaction را به برنامه اضافه کنید.
روش دیگر اعمال Transaction بر روی اتصال (Connection) پایگاه داده می باشد.
اگر دقت کرده باشید در قطعه کدهایی که تاکنون نوشته ایم هیچ گاه اتصال پایگاه داده را باز یا بسته نکرده ایم (به جز در هنگام استفاده از ExecuteXmlReader). اگر بخواهیم یک Transaction را بر روی اتصال پایگاه داده اعمال کنیم باید شکل زیر عمل کنیم.
کلاس Database دارای متدی به نام CreateConnection می باشد که یک شیء از نوع DbConnection ایجاد کرده و برمی گرداند. کافیست که Transaction خود را (که در اینجا از نوع DbTransaction می باشد) بر روی این اتصال اعمال کنیم. به قطعه کد زیر توجه کنید.
using (DbConnection conn = db.CreateConnection())
{
conn.Open();
DbTransaction trans = conn.BeginTransaction();
try
{
....
....
....
// execute commands, passing in the current transaction to each one
db.ExecuteNonQuery(command1, trans);
db.ExecuteNonQuery(command2, trans);
....
trans.Commit(); // commit the transaction
}
catch
{
trans.Rollback(); // rollback the transaction
}
}
در این روش باز و بسته نمودن اتصال به عهده خود ما می باشد و بنابراین پس از انجام عملیات باید اتصال را ببندیم. این عمل را با استفاده از بلاک using انجام داده ایم. اغلب متدهایی که دستورات را بر روی پایگاه داده اجرا می کنند دارای Overload هایی می باشند که یک پارامتر از نوع DbTransaction دریافت می کنند. برای اعمال تراکنش باید شیء DbTransaction را به این متد ها بفرستیم. در قطعه کد بالا برای متد ExecuteNonQuery این کار را انجام داده ایم.
پس از انجام عملیات، تراکنش را برای اعمال تغییرات Commit نموده ایم. اگر خطایی هنگام انجام عملیات پیش آید، ادامه کار به بلاک catch منتقل شده و تراکنش Rollback می شود.
در این مقاله ما برای تبدیل نمودن داده های بازیابی شده از پایگاه داده به اشیائی از نوع Studentاز روش پیمایش IDataReader در یک حلقه استفاده کردیم. کتابخانه Enterprise Library دارای دو متد به نام های ExecuteSprocAccessor و ExecuteSqlAccessor می باشد که این کار را در درون خود انجام می دهند. ما در این مقاله این روش را بررسی نکردیم و شما در صورت علاقه مند بودن می توانید در مورد آن تحقیق کنید.
